1 语音识别概述
语音识别技术最早可以追溯到20世纪50年代,是试图使机器能“听懂”人类语音的技术。按照目前主流的研究方法,连续语音识别和孤立词语音识别采用的声学模型一般不同。孤立词语音识别一般采用DTW动态时间规整算法。连续语音识别一般采用HMM模型或者HMM与人工神经网络ANN相结合。
语音的能量来源于正常呼气时肺部呼出的稳定气流,喉部的声带既是阀门,又是振动部件。语音信号可以看作是一个时间序列,可以由隐马尔可夫模型(HMM)进行表征。语音信号经过数字化及滤噪处理之后,进行端点检测得到语音段。对语音段数据进行特征提取,语音信号就被转换成为了一个向量序列,作为观察值。在训练过程中,观察值用于估计HMM的参数。这些参数包括观察值的概率密度函数,及其对应的状态,状态转移概率等。当参数估计完成后,估计出的参数即用于识别。此时经过特征提取后的观察值作为测试数据进行识别,由此进行识别准确率的结果统计。训练及识别的结构框图如图1所示。
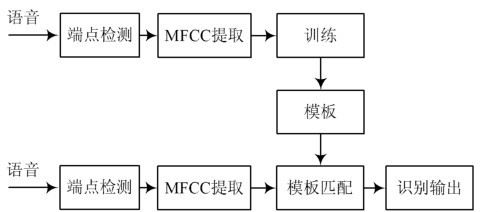
图1 语音识别系统结构框图
1. 1 端点检测
找到语音信号的起止点,从而减小语音信号处理过程中的计算量,是语音识别过程中一个基本而且重要的问题。端点作为语音分割的重要特征,其准确性在很大程度上影响系统识别的性能。
能零积定义:一帧时间范围内的信号能量与该段时间内信号过零率的乘积。
能零积门限检测算法可以在不丢失语音信息的情况下,对语音进行准确的端点检测,经过450个孤立词(数字“0~9”)测试准确率为98%以上,经该方法进行语音分割后的语音,在进入识别模块时识别正确率达95%。
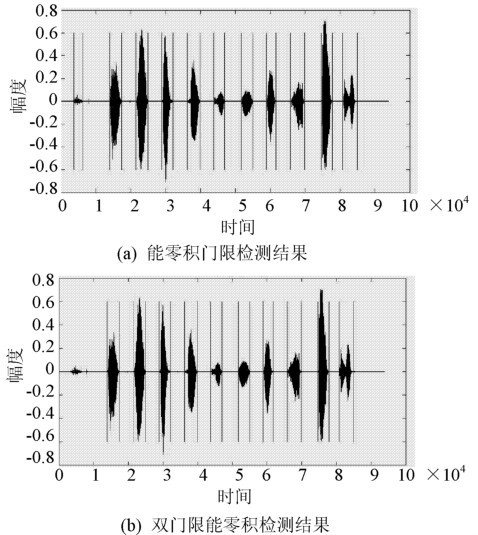
图2 检测结果的效果示意图
当话者带有呼吸噪声,或周围环境出现持续时间较短能量较高的噪声,或者持续时间长而能量较弱的噪声时,能零积门限检测算法就不能对这些噪声进行滤除,进而被判作语音进入识别模块,导致误识。图2(a)所示为室内环境,正常情况下采集到的带有呼气噪声的数字“0~9”的语音信号,利用能零积门限检测算法得到的效果示意图。最前面一段信号为呼气噪声,之后为数字“0~9”的语音。
从图2(a)直观的显示出能零积算法在对付能量较弱,但持续时间长的噪音无能为力。由此引出了双门限能零积检测算法。
所谓的双门限能零积算法指的是进行两次门限判断。第一门限采用能零积,第二门限为单词能零积平均值。也即在前面介绍的能零积检测算法的基础上再进行一次能零积平均值的判决。其中,第二门限的设定依据取决于所有实验样本中呼气噪声的平均能零积及最小的语音单词能零积之间的一个常数。如图2(b)所示,即为图2(a)中所示的语音文件经过双门限能零积检测算法得到的检测结果。可以明显看到,最前一段信号,即呼气噪声已经被视为噪音滤除。
1.2 隐马尔可夫模型HMM
隐马尔可夫模型,即HMM是一种基于概率方法的模式匹配方法。它的应用是20世纪80年代以来语音识别领域取得的重要成果。
一个HMM模型可以表示为:

式中:π为初始状态概率分布,πi=P(q1=θi),1≤i≤N,表示初始状态处于θi的概率;A为状态转移概率矩阵,(aij)N×N,aij=P(qt+1 =θj|qt=θi),1≤i,j≤N;B为观察值概率矩阵,B={bj(ot)},j=1,2,…,N,表示观察值输出概率分布,也就是观察值ot处于状态j的概率。
1.3 模型训练
HMM有多种结构类型,并且有不同的分类方法。根据状态转移矩阵(A参数)和观察值输出矩阵(B参数)的不同有不同类型的HMM。
对于CHMM模型,当有多个观察值序列时,其重估公式由参考文档给出,此处不再赘述。
1.4 概率计算
利用HMM的定义可以得出P(O|λ)的直接求取公式:
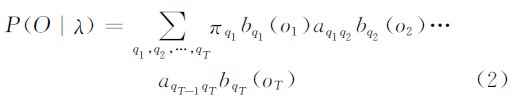
式(2)计算量巨大,是不能接受的。Rabiner提出了前向后向算法,计算量大大减小。定义前向概率:
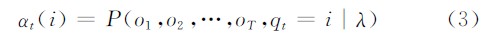
那么有
(1)初始化
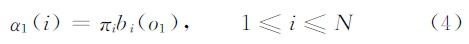
(2)递推
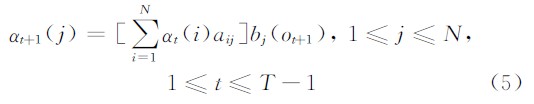
(3)终止
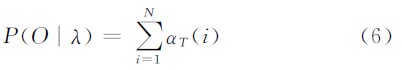
式(2)表示的是初始前向概率,bi(o1)为观察值序列处于t=1 时刻在状态i时的输出概率,由于它服从连续高斯混合分布,故此值往往极小。根据大量实验观察,通常小于10-10,此值在定点DSP中已不能用Q格式表示。分析式(3)可以发现,随着时间t的增加,还会有大量的小数之间的乘法加法运算,使得新的前向概率值at+1更小,逐渐趋向于0,定点DSP采用普通的Q格式进行计算时便会负溢出,即便不发生负溢出也会大大丢失精度。因此必须寻找一种解决方法,在不影响DSP实时性的前提下,既不发生负溢出,又能提高精度。
2 DSP实现语音识别
孤立词语音识别一般采用DTW动态时间规整算法。连续语音识别一般采用HMM模型或者HMM与人工神经网络ANN相结合。
为了能实时控制机器人,首先需要考虑的是能够实现实时地语音识别。而考虑到CHMM的巨大计算量以及成本因素,采用了数据处理能力强大,成本相对较低的定点数字信号处理器,即定点DSP。本实验采用的是TI公司多媒体芯片TMS320DM642。定点DSP要能准确、实时的实现语音识别,必须考虑2点问题:精度问题和实时性问题。
精度问题的产生原因已经由1.4节详细阐述,这里不再赘述。因此必须找出一种可以提高精度,而又不会对实时性造成影响的解决方法。基于以上考虑,本文提出了一种动态指数定标方法。这种方法类似于科学计数法,用2个32 b单元,一个单元表示指数部分EXP,另一个单元表示小数部分Frac。首先将待计算的数据按照指数定标格式归一化,再进行运算。这样当数据进行运算时,仍然是定点进行,从而避开浮点算法,从而使精度可以达到要求。
对于实时性问题,通常,语音的频率范围大约是300~3 400 Hz左右,因而本实验采样率取8 kHz,16 b量化。考虑识别的实现,必须将语音进行分帧处理。研究表明,大约在10~30 ms内,人的发音模型是相对稳定的,所以本实验中取32 ms为一帧,16 ms为帧移的时间间隔。
解决实时性问题必须充分利用DSP芯片的片上资源。利用EDMA进行音频数据的搬移,提高CPU利用率。采用PING—PONG缓冲区进行数据的缓存,以保证不丢失数据。CHMM训练的模板放于外部存储器,由于外部存储器较片内存储器的速度更慢,因此开启CACHE。建立DSP/BIOS任务,充分利用BIOS进行任务之间的调度,实时处理新到的语音数据,检测语音的起止点,当有语音数据时再进入下一任务进行特征提取及识别。将识别结果用扬声器播放,并送入到机器人的控制模块。
实验中,采用如图3的程序架构。
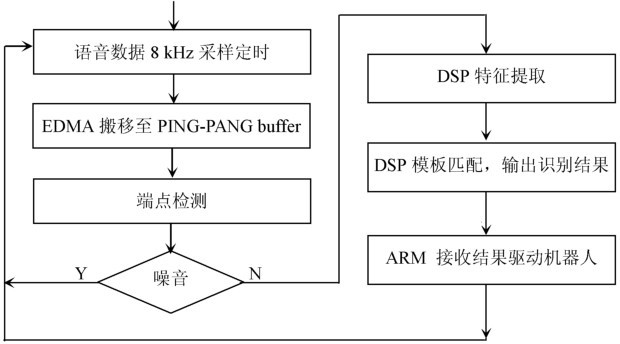
图3机器人识别软件框图
3 机器人控制
机器人由自然条件下的语句进行控制。这些语句描述了动作的方向,以及动作的幅度。为了简单起见,让机器人只执行简单命令。由手机进行遥控,DSP模块识别出语音命令,送控制命令到ARM模块,驱动左右机械轮执行相应动作。
3.1 硬件结构
机器人的硬件结构如图4所示。
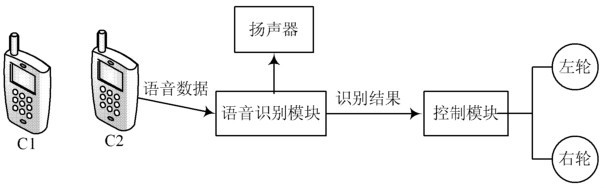
图4机器人硬件结构
机器人主要有2大模块,一个是基于DSP的语音识别模块;另一个是基于ARM的控制模块,其机械足为两滑轮。由语音识别模块识别语音,由控制模块控制机器人动作。
3.2 语音控制
首先根据需要,设置了如下几个简单命令:前、后、左、右。机器人各状态之间的转移关系如图5所示。其中,等待状态为默认状态,当每次执行前后或左右转命令后停止,即回到等待状态,此时为静止状态。
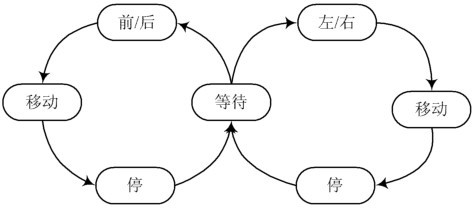
图5机器人状态
语音的训练模板库由4个命令加10个阿拉伯数字共14个组成,如下所示。
命令:“前”、“后”、“左”、“右”;
数字:“0~9”。
命令代表动作的方向,数字代表动作的幅度。当执行前后命令时,数字的单位为dm,执行左右转弯命令时,数字的单位为角度单位的20°。每句命令句法为命令+数字。例如,语音“左2”表示的含义为向左转弯40°,“前4”表示向前直行4 dm。
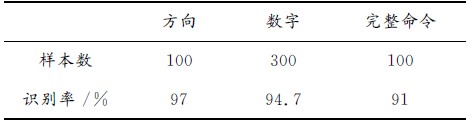
机器人语音控制的关键在于语音识别的准确率。表1给出了5个男声样本的识别统计结果。
表1识别统计结果
4 结语
工作中,成功地将CHMM模型应用于定点DSP上,并实现了对机器人的语音控制。解决了CHMM模型巨大计算量及精度与实时性之间的矛盾。提出了一种新的端点检测算法,对于对抗短时或较低能量的环境噪音具有明显效果。同时需要指出的是,当语音识别指令增多时,则需要定义更多的句法,并且识别率也可能会相应降低,计算量也会相应变大。下一步研究工作应更注重提高大词汇量时的识别率及其鲁棒性。