1、引言
早期的操作系统都是基于宏内核的思想实现的[5],例如UNIX、Linux、Solaris等。设计者将进程管理、文件系统、设备驱动程序、存储管理等功能全部放在内核中完成。随着技术的发展,操作系统性能不断的提升的同时,也带来了大量的错误[1]。把所有这些功能都放在具有最高特权级的内核中使得内核变得异常庞大,可靠性、安全性下降,可扩展性也变的十分困难[3]。因此,微内核的思想被提出。
微内核只提供基本的操作系统功能服务,采用了机制与策略分离的设计思想,相关的驱动与一些服务被移出内核,策略则由用户层来实现,使得系统中各进程相对独立,互不干扰[4],提高了系统的安全性,可靠性。但是,这种思想的实现对性能方面却产生了一些影响。在微内核中,困扰性能的两大因素主要是进程间通信以及任务切换。
相比较宏内核而言,微内核将大部分实现操作系统功能的服务移出了内核,内核仅仅实现不可避免的机制。这使得内核成了服务的中转站,因此加大了信息处理的开销,客户进程与服务进程间的通信多了道门槛,地址空间的切换也急剧增加。
随着技术的发展,微内核技术已发展到第二代。Minix 3[3]就是第二代微内核的典型代表。在保持着性能的最小损失的同时,实现了高可靠性与高稳定性。
2、对Minix 3改进
2.1 Minix 3存在的缺陷
Minix最初是由Tanenbaum教授为了教学而写的一个操作系统,发展到现在已经是第三代,它采用微内核模式,由服务器和驱动程序等进程模块和内核组成,大大提高了操作系统的可靠性[3]。
由于Minix 3采用了第二代微内核技术,用户进程及服务器进程和驱动进程都拥有自己的地址空间,它们之间相互独立且相互不可见。为了能够进行进程间通信,内核成了服务的中转站,因为只有内核才进入各进程的地址空间中。经过代码的阅读,我们认为:Minix 3的编写者为了提高效率,实现简单,仅仅使用了分段机制。这直接导致了Minix3存在以下的缺陷:
1. 分段机制并不能充分利用物理内存。将导致物理内存存在大量的浪费。
2. 微内核必须紧紧结合硬件结构,这是为了能够提升微内核的性能,而支持分段结构的CPU仅仅是Intel的IA32系列,这就大大将局限Minix3在别的CPU体系的发展。
3. 采用分段机制,并没有真正实现将各进程的地址空间相隔离。如果采用分页机制与虚拟内存,将使得每个用户进程,服务器进程与驱动进程真正的相隔离,每个进程都有自己的地址空间,更加符合微内核操作系统的设计思想。
Minix3中为了使得内核能够进入所有进程的地址空间而没有采用分页机制,仅仅使用了分段机制,这对系统的可靠性和稳定性带来了一定的隐患,并且没有分页机制的操作系统也不是一种好的设计体系,并不能有效的使用物理内存。所以必须对Minix 3进行改进,引入分页机制。
高性能和高灵活性的要求决定微内核必须尽可能缩到最小,这就将大量的服务放到了内核之外,服务进程与用户进程、内核之间将产生大量的进程间通信和任务切换,这是导致微内核性能降低的主要因素。而采用分页机制后,由于引进了页目录和页表,这必将导致内核的性能进一步下降。其次,Minix 3对分段机制下的进程间通信采取了一定的优化,但这些优化并不适用于分页机制中。因此,必须在分页机制下对进程间通信加以优化,提高操作系统的效率。
2.2 内存快速映射技术
Minix 3的进程间的通信采用了聚合的方式(rendzvous),使用固定大小的消息通信(见图1)。因此,Minix 3中的进程间通信完全通过消息完成。用户进程也用这种方式与操作系统组件进行通信。聚合原则使得消息的传递不用任何中间缓冲。
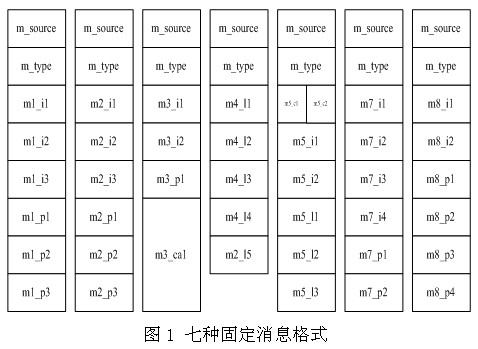
每个进程都有自己的地址空间,进程之间相互不能看见另外进程的地址空间,这就大大提高了系统的安全性和可靠性。然而,在进程间通信时,需要将A进程的消息传递给B进程时就出现了问题。在Minix 3中,由于采用的是分段机制,内核地址空间分布在物理内存中的不同的逻辑段中,通过内核,可以将A进程的消息一次直接复制到B进程中去。不需要在内核中设置消息缓冲。
在采用了分页机制后,也可以通过类似的方法复制消息,内核将进程A中的消息复制到内核共有的共享消息缓冲区中,在将消息复制给进程B。这样就实现了消息的传递。即用户进程A的地址空间→内核地址空间→用户进程B的地址空间,由于内核可以根据各进程的页目录和页表看到所有进程的地址空间,所以这种方法是可行的(见图2)。也只有通过内核,才能使消息在不同的地址空间内传递。
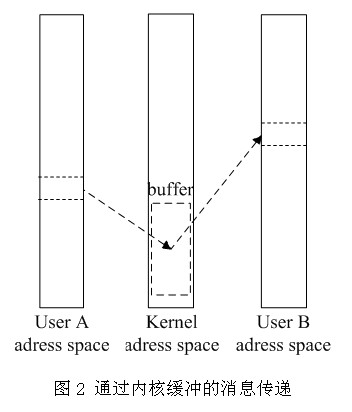
但是通过内核缓冲的方法降低了系统的性能。首先内核必须在内核空间开辟公用的消息缓冲,在很多进程都需要消息传递时,缓冲区将出现溢出情况,并且不同进程改变缓冲区的消息时,使得进程地址空间相互独立的设计思想被变相的破坏了,进程可以通过改变缓冲区中的消息来实现改变其他进程地址空间的内容,这使得微内核Minix 3原本的高可靠性和高安全性设计思想被破坏。其次,消息必须被复制两次,这两次数据拷贝可能耗时很大,拷贝消息n字节的消息必须消耗20+0.75n次CPU指令周期[2],并且还会导致TLB和cache的未命中。
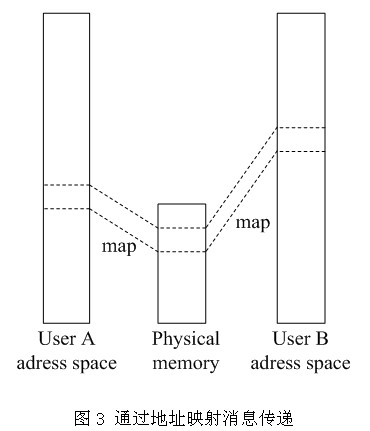
在这里我们提出一种新的设计思路。内核通过将进程A地址空间中的消息映射给B通过这种快速映射来实现消息的传递(见图3)。在映射过程为了防止进程B对进程A中的该页面进行修改而产生的不可靠性,在映射过程中采用了写时拷贝技术。资源的复制是在进程B需要写入时才会进行,在此之前,页面以只读方式共享。它将地址空间上的页的拷贝被推迟到实际发生写入的时候。
这种方法避免了在内核中设置消息缓冲,这也符合了是Minix 3在消息传递采用的聚合原则。
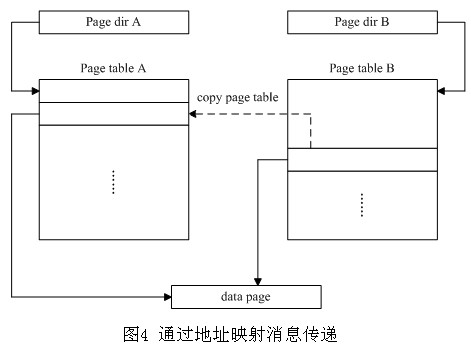
Intel系列CPU的MMU可以采用两级页表,第一级为页目录,大小为4KB,存储在物理页中,每个表项4字节长,共1024个表项。每个表项对应第二级的一个页表,第二级的每一个页表也有1024个表项,每个表项对应一个物理页。由于Minix 3采用了固定大小的消息通信,消息的大小随机器的体系结构的不同会有所不同,但消息大小肯定是在页面大小以内的。因此,一次消息的映射只需要复制一个页表,即4字节而已(见图4)。这种方法对于消息传递所付出的代价是可以忽略的。
3、实验及结果分析
测试所使用的机器配置是:CPU:Intel Celeron 1.7GHZ;Cache:256K;内存:1G。
我们让改进后的Minix 3的测试进程重复执行系统调用,以此来达到频繁切换地址空间与进程间通信的目的。例如getpid系统调用就是一个用户进程到进程管理器的一次进程通信。测试结果如表1。
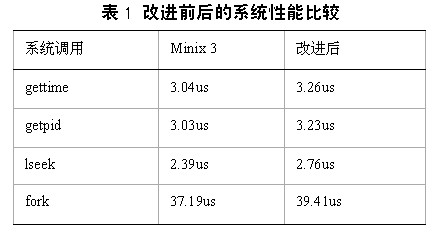
可以看到,在加入分页机制,对进程间通信和地址空间的切换进行改进后,性能的牺牲仅仅是5-10%左右,但在保证Minix 3原有的稳定性与可靠性的基础上,再次提高了稳定性和可靠性,这是非常值得的。
4、结论
微内核中困扰性能的两大因素主要是进程间通信以及任务切换。除了对进程间通信做出改进以外,也需要对任务切换进行优化。大量的任务切换直接导致了地址空间的转换,而地址空间的切换必然伴随着TLB的刷新,随着TLB容量的增加,TLB的刷新也为地址空间切换的带来了很大的开销,可以设计一种能有效避免TLB刷新的方法。